📖 Le Contexte : "Quand le volume tue la visibilité"
Les systèmes distribués modernes génèrent des flux d'événements massifs en continu — paiements, clics, erreurs, actions utilisateurs. Sans infrastructure dédiée, ces événements disparaissent dans des logs illisibles ou submergent les équipes sous des milliers d'alertes non triées. La valeur de chaque signal se noie dans le bruit.
Zenith est la réponse à ce problème : un pipeline Go cloud-native qui intercepte les événements entrants, évalue chaque événement contre un ensemble de règles métier dynamiques, et déclenche automatiquement les bonnes actions vers les bons destinataires.
Un exemple concret :
Si
purchase.amount > 500ETuser.segment == 'VIP', déclencher une alerte Slack en priorité haute. Sinon, archiver silencieusement en S3.
Ce qui distingue Zenith d'un simple webhook ou d'un worker Kafka basique, c'est l'architecture en pipeline trois couches avec un moteur de règles JSONB dynamique, une observabilité de bout en bout via OpenTelemetry, et un déploiement cloud-native reproductible sur GCP.
🏗️ Architecture : Pipeline en 3 couches
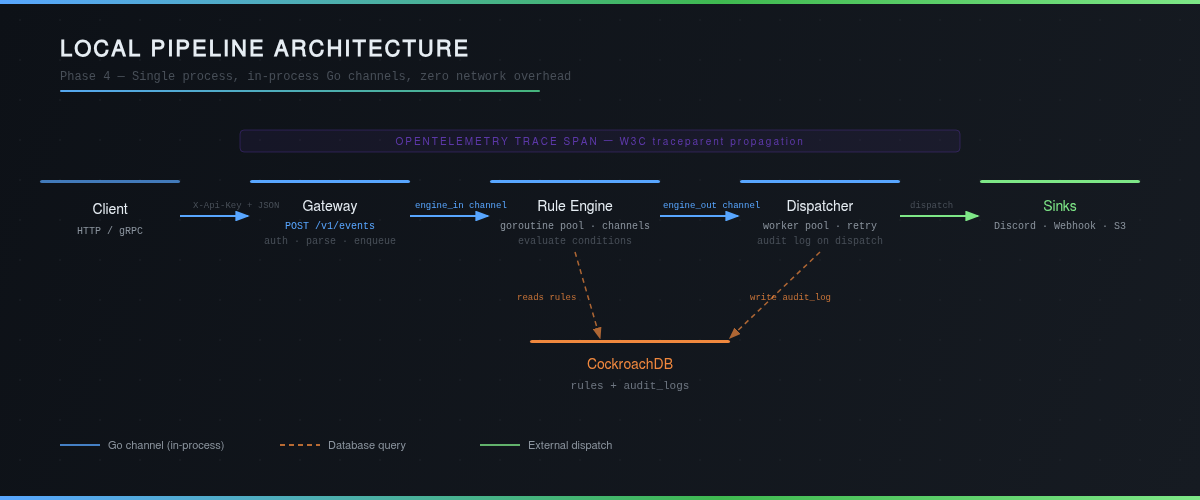
Le pipeline suit un flux linéaire et non-bloquant, où chaque couche communique avec la suivante via des channels Go in-process — zéro overhead réseau, latence sub-milliseconde.
1. Ingestor — La porte d'entrée
Le service d'ingestion implémente IngestorService via ConnectRPC, une couche qui expose simultanément un endpoint gRPC natif et un endpoint REST (HTTP/2 via h2c), sans configuration supplémentaire. Chaque requête entrante est :
- Authentifiée par
X-Api-Key(hashage bcrypt, clé liée à unSource) - Validée et parsée en
domain.Event - Enfilée dans le channel
engine_invers le Rule Engine
Un goroutine pool configurable (ENGINE_WORKER_COUNT, défaut 10) garantit que l'ingestion ne bloque jamais, même sous charge.
2. Rule Engine — Le cerveau
Le moteur de règles évalue chaque événement contre toutes les règles actives liées à sa source. Les règles sont stockées en JSONB dans CockroachDB, avec une condition structurée :
{"field": "amount", "operator": ">", "value": 1000}
6 opérateurs supportés (==, !=, >, >=, <, <=) sur des types dynamiques (numérique et string). L'évaluation de la condition pure est à zéro allocation dans le chemin critique — 13.6 ns par évaluation mesurés au benchmark.
Les événements matchés sont envoyés dans le channel engine_out vers le Dispatcher.
3. Dispatcher — Le routeur d'actions
Le Dispatcher orchestre un worker pool qui consomme les événements matchés et les route vers les sinks appropriés (Discord, webhooks HTTP, S3). Chaque dispatch implémente un retry avec backoff exponentiel et écrit un audit_log dans CockroachDB — succès ou échec, chaque action est traçable.
Le choix des channels Go
Latence sub-milliseconde (canaux in-process). Évolution prévue vers NATS/Kafka pour le scaling indépendant des composants.
Le choix des channels Go plutôt qu'une queue externe n'est pas une simplification — c'est une décision architecturale consciente, la latence prime sur la scalabilité indépendante.
🧠 Sous le capot : Les vrais défis
Défi 1 — Shutdown gracieux sans perte d'événements
Un SIGTERM en cours d'évaluation peut silencieusement perdre des événements en vol. La solution implémentée est un drain complet et ordonné du pipeline :
SIGTERM reçu
→ Stop accept (plus de nouvelles requêtes)
→ Drain engine_in (vider les événements en attente d'évaluation)
→ Drain engine_out (vider les événements matchés en attente de dispatch)
→ Exit propre
La coordination entre les goroutines utilise un context.Context avec annulation propagée — chaque stage attend la fermeture de son channel d'entrée avant de s'arrêter, garantissant qu'aucun événement en vol n'est perdu lors d'un rolling deployment Kubernetes.
Défi 2 — Évaluation de règles JSONB sans ORM
Les conditions sont stockées en json.RawMessage dans CockroachDB. Le moteur d'évaluation (internal/engine/evaluator.go) décode dynamiquement chaque condition et applique l'opérateur sur des types inférés — sans reflection, sans allocation dans le chemin chaud.
Résultat benchmark :
- Condition pure (zéro allocation) : 13.6 ns par évaluation
Evaluator.Evaluate()complet (JSON + repo lookup) : 3.2 µs- Le JSON unmarshal représente ~95% du coût — la logique d'évaluation elle-même est négligeable.
Défi 3 — Tests d'intégration avec testcontainers-go
Les tests du repository (internal/repository/postgres/) spin up une vraie instance CockroachDB via testcontainers-go, appliquent les migrations golang-migrate, puis exécutent les tests contre une base réelle. Zéro mock, zéro divergence possible entre test et production.
Ce choix est défendable : les tests unitaires avec mock de base de données masquent les bugs de migration. Ici, si la migration passe en CI, elle passera en prod.
🔭 Observabilité : Tracer chaque événement
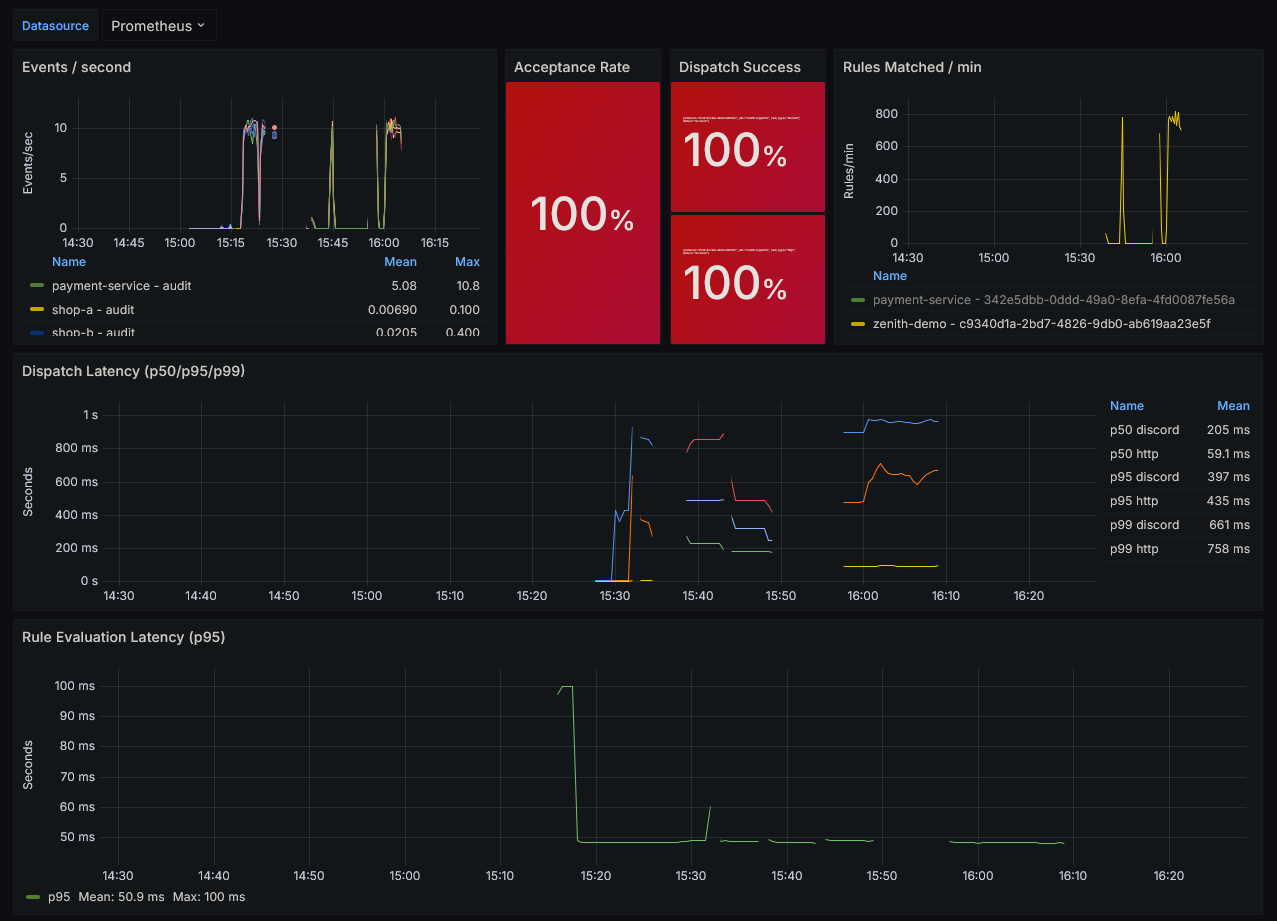
OpenTelemetry — De l'ingestion au dispatch
Chaque événement génère un arbre de spans complet, propagé via le header W3C traceparent :
| Span | Attributs clés |
|---|---|
ingestor.gateway.handle (racine) | event_id, source, event_type |
engine.evaluate_rules | source, total_rules, matched_count |
dispatcher.dispatch | rule_id, sink_type, status |
Les traces sont exportées vers GCP Cloud Trace en production (via OTLP), ou vers Jaeger en local (docker-compose inclus dans deployments/monitoring/). La propagation W3C permet de relier une requête client à son action de dispatch, à travers tous les composants du pipeline.
Prometheus — 9 métriques, 3 catégories
| Catégorie | Métriques clés |
|---|---|
| Ingestion | events_received_total, events_accepted_total, events_rejected_total (labels source, reason) |
| Évaluation | rules_evaluated_total, rules_matched_total, rule_evaluation_duration_seconds |
| Dispatch | dispatch_total (success/failed), dispatch_duration_seconds, worker_queue_depth |
Le dashboard Grafana pré-construit (deployments/grafana/zenith-dashboard.json) visualise l'intégralité du pipeline en un écran : throughput, acceptance rate, dispatch success rate, latence p95/p99, et profondeur de queue en temps réel.
☁️ Infrastructure : Cloud-Native sur GCP
| Composant | Technologie | Rôle |
|---|---|---|
| Runtime | Go 1.24 | Ingestor + Dispatcher binaries |
| Base de données | CockroachDB Serverless | ACID, distribuée, PostgreSQL-compatible |
| Containers | Kubernetes (Kind local / GKE cloud) | Orchestration, HPA, resource limits |
| Cloud | Cloud Run + Artifact Registry | Déploiement serverless scalable, images taguées SHA git |
| Secrets | GCP Secret Manager | Injection sécurisée de DATABASE_URL et API_KEY_SALT |
| CI/CD | GitHub Actions + Workload Identity | Déploiement keyless, zéro credential stocké |
| IaC | Terraform | Provisioning reproductible de l'intégralité de l'infra GCP |
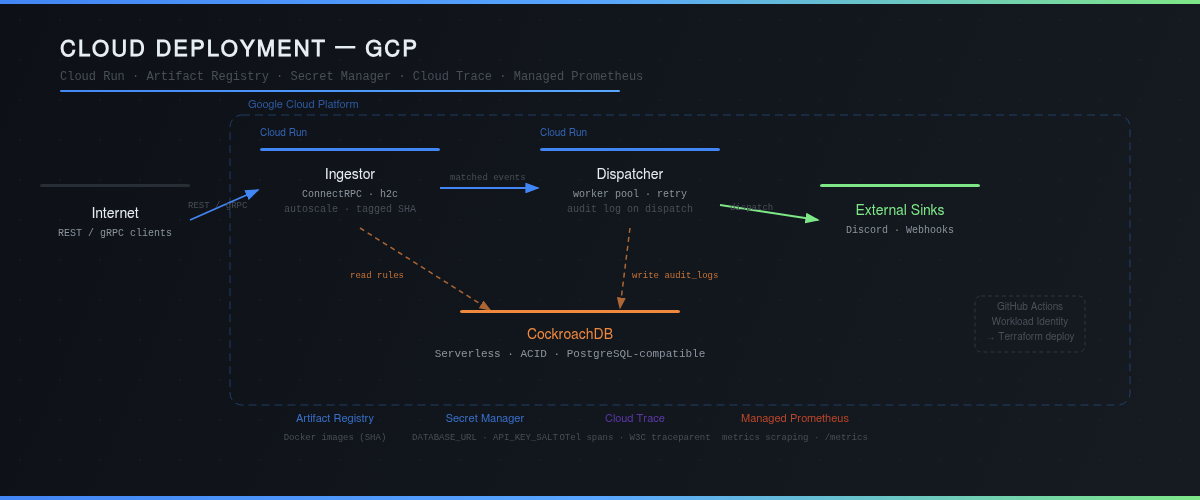
CI/CD sans credentials
Le pipeline GitHub Actions authentifie la CI via Workload Identity Federation — aucun service account key n'est jamais stocké dans les secrets GitHub. La CI appelle directement Terraform avec project_id et image_tag (SHA git), le reste est géré par Secret Manager côté GCP.
HPA — Scaling automatique sous charge
L'Horizontal Pod Autoscaler est configuré sur la métrique CPU (target 60%), avec min 1 / max 5 replicas. Sous charge croissante :
| RPS | CPU | Replicas | État |
|---|---|---|---|
| 200 | 40% | 1 | Nominal |
| 400 | 65% | 2 | Scale-out déclenché |
| 600 | 50% / pod | 3 | Rééquilibré |
| 1000 | 45% / pod | 5 | Capacité maximale |
Temps pour un nouveau replica opérationnel : ~45 secondes (15s check HPA + 10s démarrage pod).
📊 Performance : Les chiffres

Rule Engine
| Mesure | Résultat | Allocations |
|---|---|---|
| Condition pure (1 règle) | 13.6 ns | 0 |
Evaluator.Evaluate() complet | 3.2 µs | 30 |
| 100 règles évaluées | 14.0 µs (condition) / 98.9 µs (complet) | 357 / 1157 |
Le zéro-allocation sur le chemin critique signifie qu'ajouter de nouveaux opérateurs ou types de conditions ne dégradера pas les performances — la logique d'évaluation est découplée du coût d'allocation.
Gateway
Le bottleneck réel n'est pas le CPU — c'est le round-trip CockroachDB (~10 ms) pour ListBySourceID() à chaque événement. À 50 RPS, la latence p50 est 50–100 ms. Le HPA entre en jeu avant que les queues ne saturent.
REST vs gRPC
Les deux protocoles utilisent HTTP/2 via h2c (ConnectRPC). La différence de latence mesurée est < 1% — le coût de sérialisation Protocol Buffers est négligeable face au round-trip base de données. Le choix entre REST et gRPC se fait sur les contraintes client, pas sur les performances serveur.
🚀 La Suite : Message Broker
L'architecture actuelle couple l'Ingestor et le Rule Engine dans un seul processus via channels. C'est optimal pour la latence, mais scaler l'ingestion scale aussi l'évaluation — les deux composants sont liés.
Découplage via message broker :
[Ingestor] → [NATS / Kafka / GCP Pub/Sub] → [Rule Engine] → [Dispatcher]
Tradeoff : +~100 ms de latence (hop réseau + buffering) contre une scalabilité horizontale totalement indépendante. À partir d'une certaine échelle (>1000 RPS soutenu), ce tradeoff devient évident.
D'autres améliorations prévues : cache des règles en mémoire (évite le round-trip DB par événement), règles composites (AND/OR de conditions), et évaluation multi-sink sur un même événement.
Expertise technique : Go (goroutines, channels, interfaces), ConnectRPC/gRPC, Protocol Buffers, CockroachDB, SQL raw (pgx/v5), OpenTelemetry, Prometheus, Grafana, Kubernetes (CKAD), Terraform, GCP (Cloud Run, Secret Manager, Cloud Trace, Artifact Registry, Workload Identity), GitHub Actions, testcontainers-go, Docker, golang-migrate.